We investigated how to introduce editable layer structure into diffusion models for video editing, where
generated edit layers must support coherent compositing with the source video. Vera provides a concrete
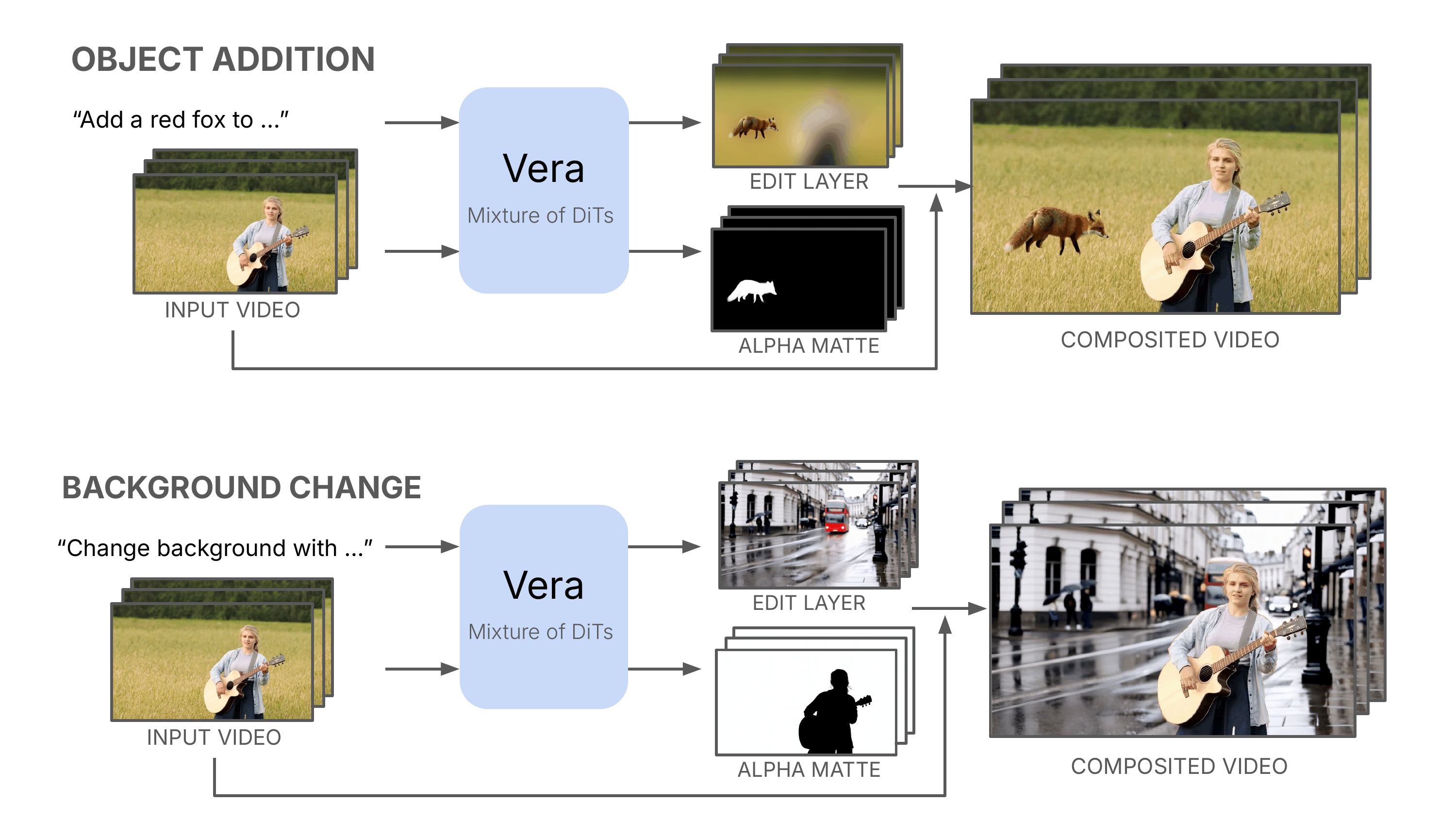
formulation: it jointly produces an edit layer, an alpha matte, and a composite video, separating what to
generate from what to preserve. The resulting editable layers can support iterative refinement in downstream
editing workflows. Through controlled experiments, we identified three key ingredients that enable layer
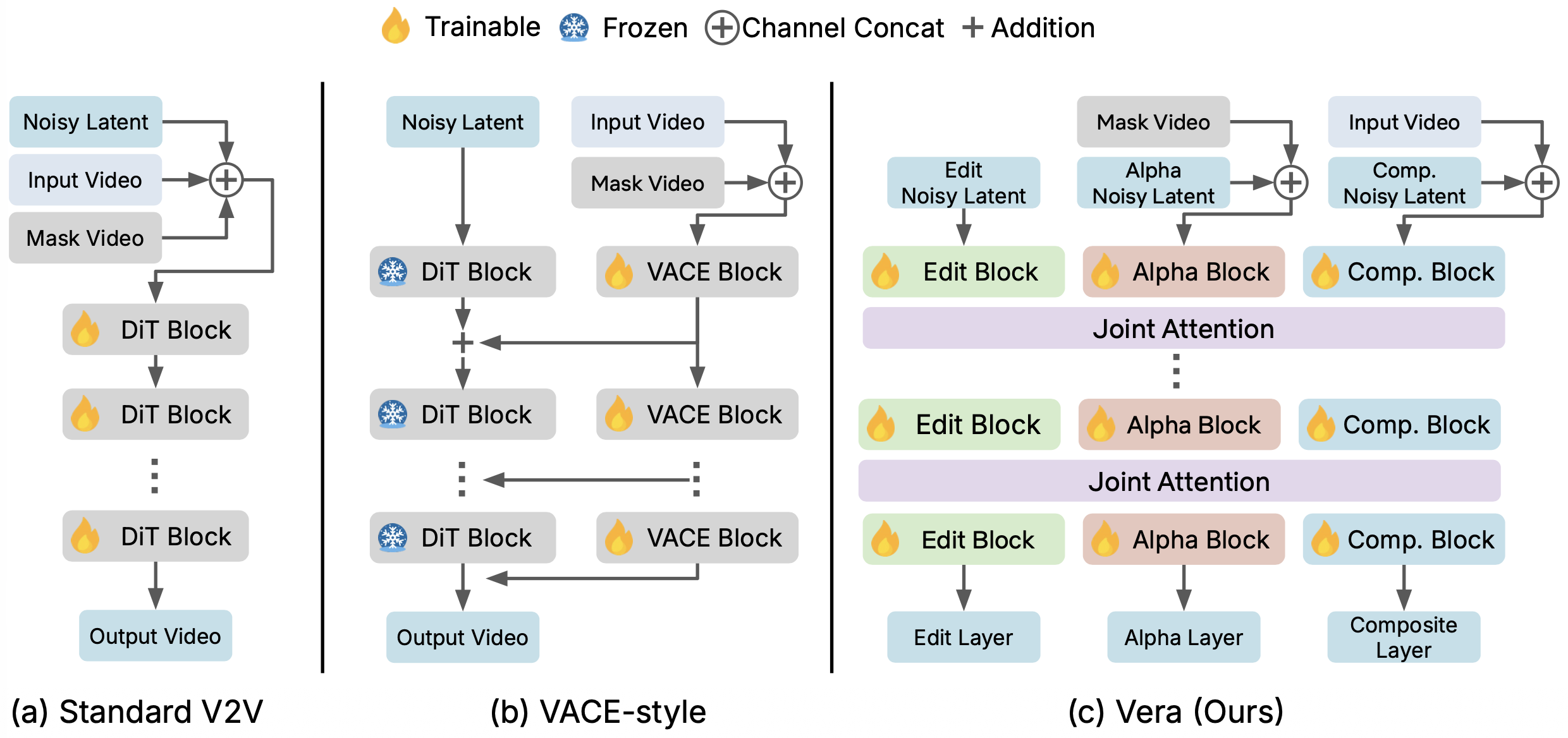
separation while retaining competitive composition quality: an MoT architecture with cross-layer interaction
through joint self-attention, composite-branch supervision, and curated layered data with accurately aligned
edit layers and alpha mattes.
Three limitations remain in this work. First, jointly generating three layers increases inference cost:
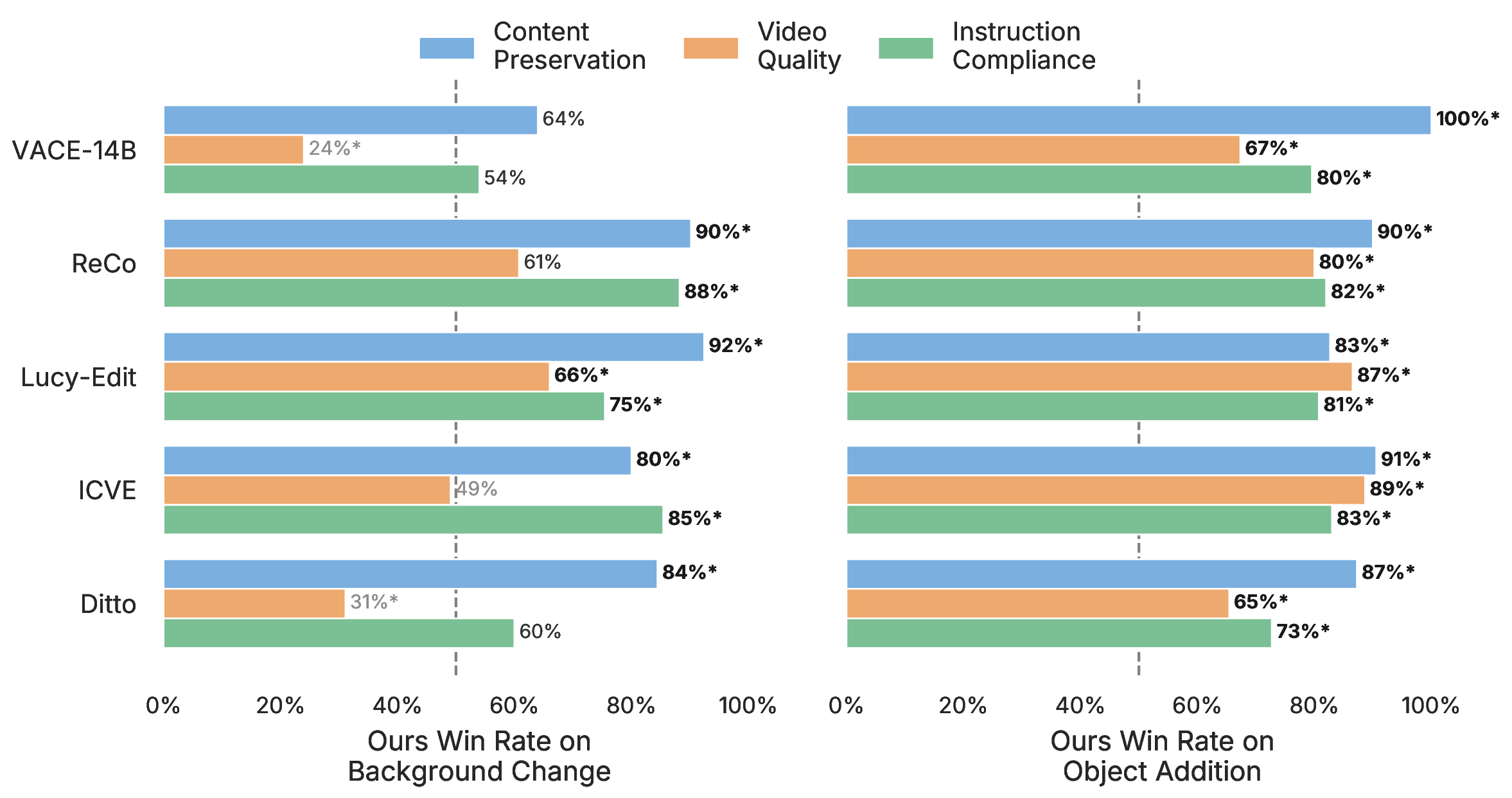
Vera-1.3B is roughly 3x slower than VACE. Second, our evaluation is limited to object addition and
background replacement. Extending the approach to relighting, complex visual effects, and broader editing
operations will require layered supervision that captures the corresponding interactions. Third, our
inference procedure approximates the preserved video with the source video and therefore assumes that
preserved content contains only small semi-transparent regions. Direct recovery in cases such as glass or
water requires suitable layered training data and explicit evaluation. Addressing these boundaries would
extend layered generation toward a broader set of production editing operations.